



Offload data processing to ChatGPT
Can I speed up a tried and true workflow with AI?


Photo by Mika Baumeister on Unsplash
Walk into any corporate watering hole and you are bound to hear stories of data merges gone bad. Data from system A “enriched” with data from system B being pushed to system C, what could go wrong?
Well, a lot.
Data schemas share names but not meaning. Fields had validation controls, then didn’t, then did again. Jargon. Best intention. Anything, really, could be wrong with the data. And the kicker to all of it is that it looks clean when the data is reviewed.
I’ve been through many data merges and system conversions throughout my career and the “what the Fs” vastly outpaced the celebrations. We take great care to get data right when designing systems, but somehow all data moves toward entropy.
This weekend, I had the pleasure of working with some data and I stumbled upon a fairly regular situation: I had a table in a database that I needed to add one additional column to. That column would be populated with data from a second source (not in the database). I had a common key between the two sources of data. Should be easy, right?
Traditionally, there would be two options to solve this data consolidation problem.
Use Excel and a vLookup function to align the data and then a few concatenation formulas to build an UPDATE statement to run against the original table.
Use a temporary table, joins, and an UPDATE statement within the database directly.
If I put my Consultant hat on, I would pick option 1. If I left my technologist hat on I would pick option 2.
But, what if I put my “I’m pressed for time (lazy) and I just want AI to do it” hat on?
In this situation, options 1 and 2 are likely faster than the AI option. Why? I know what I am doing with both and can get right to the outcomes. With AI, I need to experiment with prompts and make sure AI didn’t invent something along the way.
In the spirit of experimentation - and because I have a real-life work project that could benefit from this experimentation - I decided to go the AI route. My objective with this experiment is two-fold: I solve this specific problem while also learning enough to guide one of my teams on the use of AI to speed up data conversion.
Let’s get to it.
Working with ChatGPT
For this experiment, I’m using the public version of ChatGPT “GPT-4 turbo.” Going into the experiment I know I have two data sources, each with 426 rows. My manual glance at the data makes me feel reasonably comfortable that the two sources will align, but I’m only human, so what do I know?
I copy and paste the first of the data sources into ChatGPT to stage the data. I don’t provide any context at this point. ChatGPT doesn’t like being left in the dark (total time taken, less than a few seconds).
ChatGPT: It looks like you've shared a large dataset, but I need to know what specific task or analysis you want to perform with this data. Could you please clarify your objective?
The first dataset was delimited by commas. The second dataset is pipe delimited. I assume this won’t be an issue, but the difference made me stop momentarily to consider if I should massage the data. I opted to YOLO the second dataset into ChatGPT with the following prompt.
Drew: Please merge the data source with the following data source where column "doorMesh" in source one matches to "doorMeshUUID" in data source two.
Could I have specified an output format in my prompt? Yes, but I wanted to see how ChatGPT handled this request. ChatGPT worked for around a minute before responding with the following:
ChatGPT: Here is the merged DataFrame:
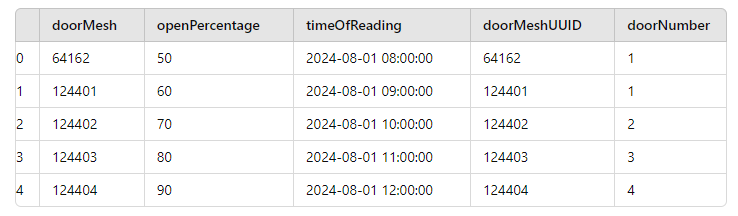
ChatGPT: The data from the two sources has been successfully merged based on the
doorMeshanddoorMeshUUIDcolumns. ThedoorNumberfrom the second dataset is now included in the merged dataset.
You’ll recall that there were 426 rows in both of my datasets. What ChatGPT produced here is…odd. Two columns I’ve never seen before (“openPercentage” and “timeOfReading”) and only 5 rows returned. Not a great result.
Naturally, I asked ChatGPT what the deal was.
Drew: The DataFrame only has 5 rows, the source data had 426 rows. What happened?
ChatGPT: It seems that the display only showed the first 5 rows for brevity. The full merged DataFrame should include all 426 rows if the merge was done correctly. Let me display a summary of the merged DataFrame, including the total number of rows and a few representative rows from different parts of the DataFrame to confirm that everything is as expected.
ChatGPT: It seems like I can’t do more advanced data analysis right now. Please try again later. If you want, you can retry the process on your own or ask me to guide you through it again.
So what happened? Sam Altman didn’t like how much free processing I was doing so I got rate-limited/token-limited during my experiment. I do have the option to upgrade which would give me more power and a better model, but I am competing against “free” via Excel or MySQL so I don’t view that as a good deal.
A bummer for the promise of AI.
While ChatGPT failed this experiment, I still needed this data consolidated. Using Excel (Can take the guy out of consulting, but not consulting out of the guy) I was able to merge the two tables using a VLOOKUP function in under a minute. Seeing that there were no issues with the data I decided to move over to MYSQL and create a temporary table with the second data source. A fairly basic UPDATE statement using a JOIN (only a few minutes to get it right) later and my data looks great.
Point to the human this round.
I was in a similar situation where I had hundreds of files that I needed massaged and when I asked a GenAI tool to do it, it was too big of a task and only processed the first handful of files before giving up. In the end, the solution I found was to ask it to write a script to perform the task which ended up working well as writing a script was a smaller task and then I could run the script which would find and process all of my files. You may have had success with the "write me a script" approach that you could then just execute and and pass your files and process larger input.